python爬虫selenium库使用记录
python爬虫selenium库使用记录
起因
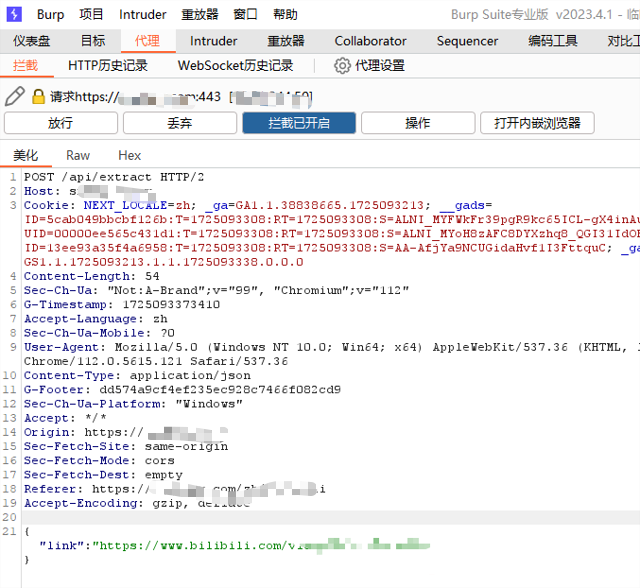
在收藏的一个网站(输入b站视频链接提取视频)中,抓包发现似乎存在很多验证内容,使用简单的爬虫发包不能拿到视频文件。所以想尝试使用selenium库控制浏览器模拟真实用户
安装selenium库及webdriver
python安装selenium库
pip install selenium安装chromeDriver
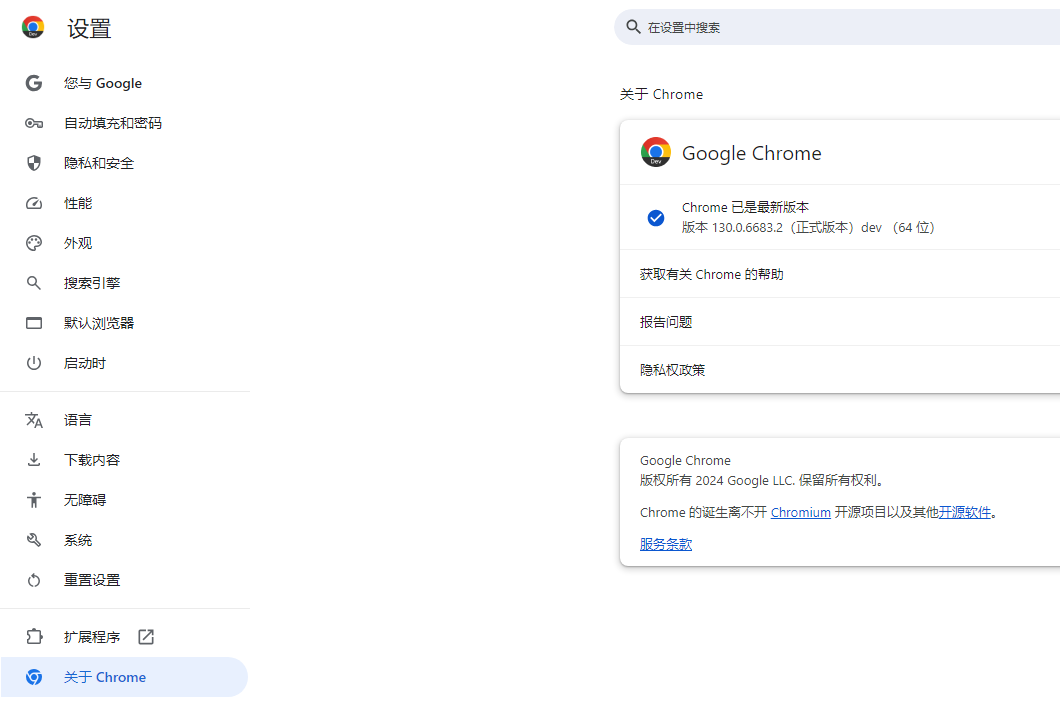
在chrome》设置 》关于里查看chrome版本,下载相同大版本的chromeDriver
chromeDriver下载地址:https://googlechromelabs.github.io/chrome-for-testing/
解压到一个目录里,记住路径,例如我的路径是F:\python_path\web_driver\chrome\130.0.6683.2
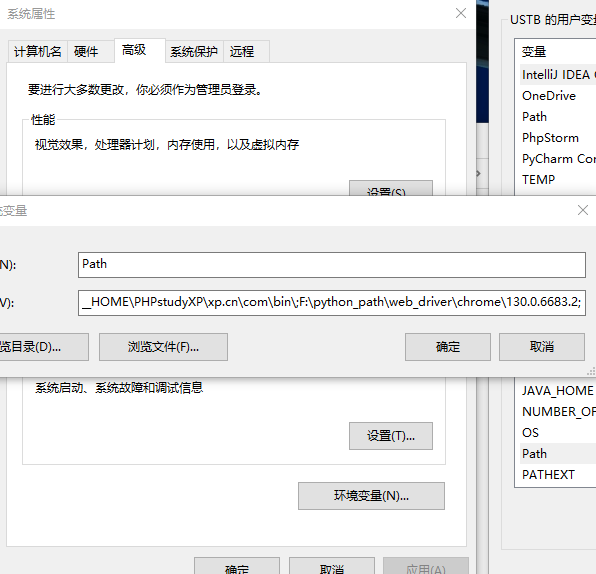
添加环境变量
把chromeDriver的解压路径放入到系统变量里的path
完成上面三步就可以使用selenium和chromedriver写脚本了
测试selenium
写一个简单测试,打开baidu页面停留三秒。使用脚本打开浏览器需要selenium的webdriver驱动库
import time
# 导入webdriver
from selenium import webdriver
url = "https://baidu.com"
# 创建一个webdriver对象
driver = webdriver.Chrome()
# 打开网页
driver.get(url)
# 页面停留3秒
time.sleep(3)
# 关闭页面
driver.close()selenium定位和操作
定位和操作需要导入By库
find_element方法
在本地nginx的index.php中写入
<form method="get">
<table>
<input type="text" name="test">
</table>
</form>
<?php
if (isset($_GET['test']))
echo $_GET['test'];
?>测试selenium定位操作功能,定位这里的input框,他使用了name属性,可以使用driver.find_element(By.NAME,name)来定位
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
# 启动 Chrome 浏览器
driver = webdriver.Chrome()
# 打开本地网页
driver.get("http://localhost")
# 等待页面加载
time.sleep(1)
# 定位输入框,输入内容
element = driver.find_element(By.NAME, "test")
element.send_keys("Hello, Selenium!") # 在输入框中输入内容
# 提交表单
element.submit()
# 等待页面加载并输出提交后的内容
time.sleep(1)
# 打印页面源码,验证PHP代码的输出
print(driver.page_source)
# 等待10秒后关闭浏览器
time.sleep(3)
driver.quit()其他常见元素定位
element = driver.find_element(By.ID, "username")
element = driver.find_element(By.NAME, "password")
element = driver.find_element(By.CLASS_NAME, "submit-button")
element = driver.find_element(By.TAG_NAME, "button")
element = driver.find_element(By.LINK_TEXT, "Click Here")
element = driver.find_element(By.PARTIAL_LINK_TEXT, "Click")
element = driver.find_element(By.CSS_SELECTOR, "#login-form .submit-button")
element = driver.find_element(By.XPATH, "//button[@id='submit']")find_elements 方法
find_elements()与find_element()类似,但它返回所有匹配的元素列表(即使只有一个元素符合条件)。使用时请注意与find_element()区分
定位
通过测试发现,网页仅有一个input,测试输入
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
url = "xxxxx"
# 创建一个webdriver对象
driver = webdriver.Chrome()
# 打开网页
driver.get(url)
time.sleep(1)
# 通过测试发现返回的<list>elements只有1个input
elements = driver.find_elements(By.TAG_NAME,"input")
print(len(elements))
element = driver.find_element(By.TAG_NAME,"input")
element.send_keys("xxxxx")
time.sleep(2)
# 关闭浏览器
driver.quit()定位button,返回数据中显示有5个button,不过还好,拿到了他们的内容
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
url = "xxxx"
# 创建一个webdriver对象
driver = webdriver.Chrome()
# 打开网页
driver.get(url)
time.sleep(1)
# 测试有几个button按钮
elements = driver.find_elements(By.TAG_NAME,"button")
print(len(elements))
for element in elements:
print(element.text)
time.sleep(3)
driver.quit()提取视频图片
电脑上部分浏览器点下载视频按钮后,跳转到视频播放页面,如何下载到本地呢?
Android手机可以下载保存视频吗?
iOS设备(iPhone、iPad)上点击下载视频按钮后,跳转到视频页面,并没有直接下载,怎么办?
下载后的文件打不开怎么办?那么我们要的就是第一个按钮提交数据
现在改写脚本,现在已经接近成功
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
url = "xxxx"
# 创建一个webdriver对象
driver = webdriver.Chrome()
# 打开网页
driver.get(url)
time.sleep(1)
# 通过测试发现只有1个input
element_tag = driver.find_element(By.TAG_NAME,"input")
element_tag.send_keys("xxxx")
time.sleep(2)
# 只要第一个按钮
button_tag = driver.find_element(By.TAG_NAME,"button")
button_tag.click()
time.sleep(3)
driver.quit()最终版本脚本,已经能够正常爬取视频
import time
import requests
from selenium import webdriver
from selenium.webdriver.common.by import By
url = "xxxx"
# 创建一个webdriver对象
driver = webdriver.Chrome()
# 打开网页
driver.get(url)
time.sleep(1)
# 通过测试发现只有1个input
element_tag = driver.find_element(By.TAG_NAME,"input")
element_tag.send_keys("xxxx")
time.sleep(2)
# 只要第一个按钮
button_tag = driver.find_element(By.TAG_NAME,"button")
button_tag.click()
# 给足够的时间加载
time.sleep(5)
# 执行 JavaScript 查找视频标题,作为文件名
script = """
function getElementContent() {
var element = document.querySelector("div.text-center.text-sm");
if (element) {
return element.textContent;
} else {
return "元素未找到";
}
}
return getElementContent();
"""
filename = driver.execute_script(script)
filename = filename.replace(" ","")
filename = filename + ".mp4"
# 使用 JavaScript 执行器获取视频 URL
script = """
var element = document.querySelector('[download="SnapAny.mp4"]');
if (element) {
return element.href; // 获取 <a> 标签的 href 属性
} else {
return null;
}
"""
video_url = driver.execute_script(script)
# 确保视频 URL 不为空
if video_url:
print("视频 URL:", video_url)
# 使用 requests 下载视频,bili会检测user-agent
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36",
}
response = requests.get(video_url, stream=True,headers=headers)
# 路径问题
save_path = "./" + filename
with open(save_path, "wb") as file:
for chunk in response.iter_content(chunk_size=8192):
if chunk:
file.write(chunk)
print("视频下载完成。")
else:
print("未找到视频 URL。")
# 关闭浏览器
driver.quit()到此,已经实现了输入url自动获取视频信息,如视频标题,视频url,把视频标题作为文件名,通过requests库来下载视
这个脚本我用来作为一个小接口,如果你有需求的话,这个脚本可能不适合直接拿来用
在ubuntu22.04跑时,修改了一点,无头模式。
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
import sys
import time
import requests
url = "xxxx"
save_path = sys.argv[1]
get_url = sys.argv[2]
# 设置无头模式
chrome_options = Options()
chrome_options.add_argument("--headless")
chrome_options.add_argument("--no-sandbox")
chrome_options.add_argument("--disable-dev-shm-usage")
# 创建一个 webdriver 对象
driver = webdriver.Chrome(service=Service('/usr/local/bin/chromedriver'), options=chrome_options)
# 打开网页
driver.get(url)
time.sleep(1)
# 通过测试发现只有1个 input
element_tag = driver.find_element(By.TAG_NAME, "input")
element_tag.send_keys(get_url)
time.sleep(2)
# 只要第一个按钮
button_tag = driver.find_element(By.TAG_NAME, "button")
button_tag.click()
# 给足够的时间加载
time.sleep(10)
# 执行 JavaScript 查找视频标题,作为文件名
script = """
function getElementContent() {
var element = document.querySelector("div.text-center.text-sm");
if (element) {
return element.textContent;
} else {
return "元素未找到";
}
}
return getElementContent();
"""
filename = driver.execute_script(script)
filename = filename.replace(" ", "")
filename = filename + ".mp4"
# 使用 JavaScript 执行器获取视频 URL
script = """
var element = document.querySelector('[download="SnapAny.mp4"]');
if (element) {
return element.href; // 获取 <a> 标签的 href 属性
} else {
return null;
}
"""
video_url = driver.execute_script(script)
# 确保视频 URL 不为空
if video_url:
# 测试后注释
# print("视频 URL:", video_url)
# 使用 requests 下载视频
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36",
}
response = requests.get(video_url, stream=True, headers=headers)
save_path = save_path + "/" + filename
with open(save_path, "wb") as file:
for chunk in response.iter_content(chunk_size=8192):
if chunk:
file.write(chunk)
print("视频下载完成。")
else:
print("未找到视频 URL。")
# 关闭浏览器
driver.quit()